MENU
|
Getting Started:
FAQ | Forum
Customizing K2PDFOPT:
Adjusting the output:
Processing Options:
|
|
| |
NATIVE PDF OUTPUT
As of v1.60, k2pdfopt has an option so that rather than rendering the output file as
a sequence of bitmaps, each output page is rendered directly using the source PDF file
instructions, but with translation, scaling, and cropping directives to place the source
regions at the appropriate places on the output pages.
This is especially beneficial if the source file is a native
text PDF file (rather than a scan of a document). In this case, the text in the output
file will be searchable, selectable, and have the identical fidelity to the input file.
On the other hand, native PDF output is not compatible with text wrapping, contrast
adjustment, gamma adjustment, or sharpening. Also, if too many pieces of a single source
page are pieced together on one output page, it can be difficult to select or
search the text as well, it takes longer to render, and it may even cause your device to run out of memory, hang, or re-start.
The video below covers the examples
that follow it.
UPDATE: In all of the examples below, with k2pdfopt v2.x, OCR
is no longer necessary to get searchable text in the default k2pdfopt output (with
re-flowed text). If the source PDF document has searchable or highlightable text (as do all
of the examples below), then either k2pdfopt output type (native PDF or the default
re-flowed text mode) should also have searchable text without having to resort
to time-consuming OCR.
K2PDFOPT NATIVE PDF OUTPUT MODES (VIDEO)
|
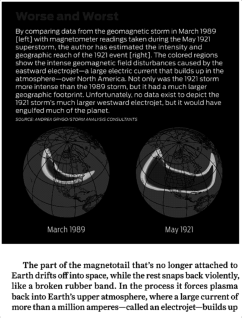
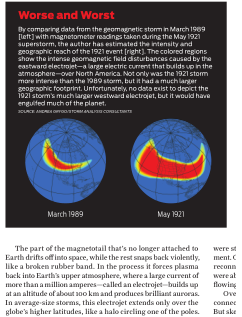
EXAMPLE 1: 2-COLUMN SCIENTIFIC ARTICLE
Below are three examples of using k2pdfopt to convert a two-column scientific article.
The default conversion (top left) creates rasterized output and has selectable text
because I used the -ocr option. The first native output conversion (top right) uses
-mode 2col and is the native output option which has the best select/search capabilities
(after the first page). Try viewing this PDF at very high magnification. You'll
see that it does not lose fidelity, unlike the default conversion. This is one
of the benefits of native output.
The third conversion, with -vb 1.5, scales some of the text to be
more readable, but is much more difficult to select text in. It's also larger and
takes longer to render than the other native output option, which defaults to -vb -2.
The -vb -2 option preserves all vertical spacing in each source region and therefore
requires fewer distinct cropping regions to be placed onto each destination page.
With -vb 1.5, on the other hand,
k2pdfopt places lines of text individually in the destination
file rather than entire regions, which has the benefit of scaling some lines to a more
reasonable size and fitting more text onto each page.
The -mode 2col command-line option (selectable using "mo" on the user menu)
is shorthand for -n -wrap- -col 2 -vb -2 -t.

Default (non-native) with -ocr option. (409 kiB)
|
|

Native: -mode 2col (129 kiB)
|

Native: -mode 2col -vb 1.5 (167 kiB)
|
|
|
EXAMPLE 2: SINGLE COLUMN (FIT WIDTH MODE)
Below are two examples for converting a single-column text file.
The one on the left again uses
the default conversion (rasterized output) with OCR and text wrapping. The conversion
on the right uses -mode fw (fit width), which has native output and
emulates the same option
on the soPdf
program, eliminating the left and right margins and turning the file
on its side (landscape mode) for enhanced readability. Notice that the native output
file is much smaller in this case.
The -mode fw command-line option (selectable using "mo" on the user menu)
is shorthand for -n -wrap- -col 1 -vb -2 -t -ls.

Default (non-native) with -ocr option. (255 kiB)
|
|

Native: -mode fw (48 kiB)
|
EXAMPLE 3: GRIDDED OUTPUT
The final example shows a 2 x 2 gridded conversion of
a two-column magazine article (excerpt).
Again, the conversion on the left is
the default conversion (rasterized output) with OCR and text wrapping for comparison.
The conversion
on the right uses -grid 2x2x4, which grids each page into 2 columns
by 2 rows with 4% overlap, quite similar to what can be accomplished
with Cut2Col.
The advantage of gridding is that only one
source region will be placed on each output page, which makes text searching and
selection the most reliable. Note in this example, because the source file has
high-resolution bitmaps, the native output is actually larger than the k2pdfopt
rasterized output. Also, notice that the source coloring is always preserved in the
native output (not converted to grayscale to save space).
Default (non-native) with -ocr option. (448 kiB)
|
|
Native: -grid 2x2x4 (1187 kiB)
|
|
|
|
|