MENU
|
Getting Started:
FAQ | Forum
Customizing K2PDFOPT:
Adjusting the output:
Processing Options:
|
|
| |
OPTICAL CHARACTER RECOGNITION (OCR)
NOTE: In v2.50, k2pdfopt is compiled with Tesseract v4.0.0.
Since v1.50, k2pdfopt can use one of two OCR engines to convert bitmapped text to
native ASCII characters so that the text in the output file can be searched
or copied and pasted into other applications. And in v1.63, bitmapped text
from any language that Tesseract supports (including, for example, Chinese) is converted
to Unicode-16 values and can be copied and pasted into Unicode-aware applications
(e.g. most web browsers and modern word processing software).
See the examples below.
UPDATE: Make sure you really need to perform OCR first.
With k2pdfopt v2.x, if the source PDF document has
searchable or highlightable text (e.g. if it is computer-generated or scanned but has
an OCR layer), then k2pdfopt output of either type (native PDF or the default
re-flowed text mode) should also have searchable text without having to resort
to time-consuming OCR. OCR should only be necessary if the source document is
scanned and does not already have a text/OCR layer.
UPDATE 2: As of k2pdfopt v2.52, Tesseract training files are
automatically downloaded as needed. See below.

(k2pdfopt -ocr pooh.pdf)
|
OCR ENGINE CHOICE: TESSERACT VS. GOCR
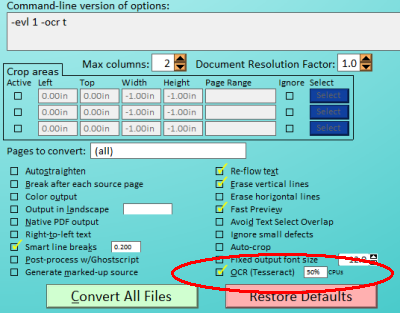
OCR is not turned on by default. You must select it with the -ocr command-line option,
or via "oc" in the interactive text menu, or as shown below in the Windows GUI:
You can choose from two different OCR engines to do the conversion to text.
The best and
default is Google's open-source Tesseract. It requires support files to be installed on your PC (see below).
The other option is GOCR,
which is slightly faster than Tesseract, but should
really only be used as a last resort because it is not very accurate--see below.
Tesseract by default runs multi-threaded to make use of multi-core CPUs in order to
run faster. Also note that some training files perform OCR faster than others.
Tesseract also supports unicode and multiple languages (GOCR only supports English / ASCII).
See the examples below where I've copied and pasted the selected text from a k2pdfopt output
file into Microsoft Word.
Tesseract is clearly far superior to GOCR (which is why it is the only selection the GUI offers). GOCR should only be used a last resort.

pooh_k2opt.pdf
Converted from pooh.pdf |
|

Tesseract 4.00
Conversion time: 6.8 s
k2pdfopt -ocr pooh.pdf |
|

GOCR 0.50
Conversion time: 4.5 s
k2pdfopt -ocr g pooh.pdf |
USING TESSERACT
NOTE!
You do not need to install the Tesseract engine to use Tesseract OCR with k2pdfopt. The
engine is built into the k2pdfopt software.
As of k2pdfopt v2.52, there are no additional files and no extra
setup required to use Tesseract OCR.
You will be prompted to download any training files needed by k2pdfopt that
are not already present on your system. The rest of this section shows you how to
install the Tesseract training files manually, but you should not have to do this
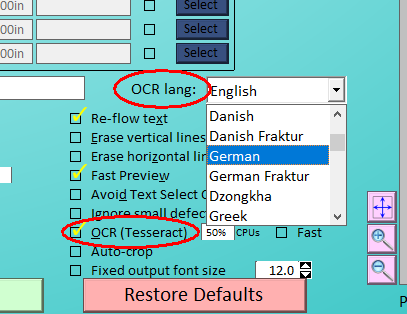
with k2pdfopt v2.52. Simply select your desired OCR language in k2pdfopt as
shown below and k2pdfopt will do the rest.
|
GETTING TESSERACT LANGUAGE FILES MANUALLY
See the Tesseract Wiki for an explanation of the Tesseract project and how to install language training files.
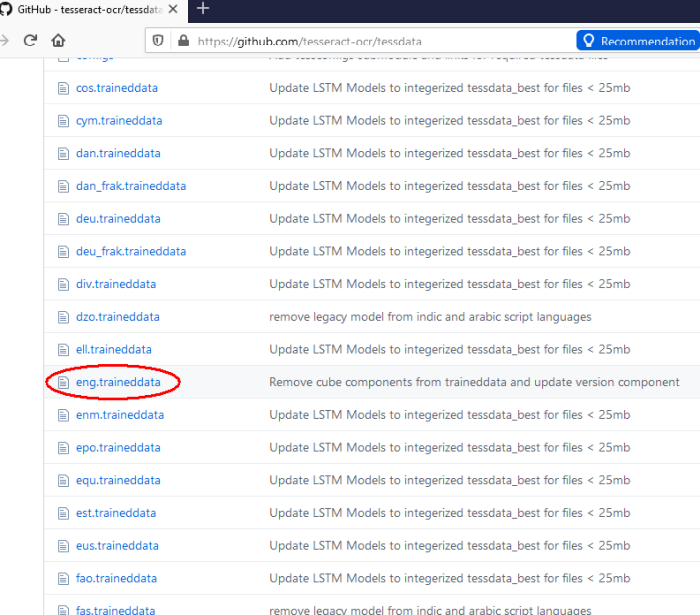
Tesseract data download page
(the English training file is circled below):
You can choose the language you prefer (e.g. English is circled above).
Fortunately, in Tesseract v4.0, there is only one training file per language rather
than multiple ones as there were in v3.0.
Tesseract 4 uses what is called
LSTM (Long Short-Term Memory) training data. The .traineddata file may have LSTM
data for Tesseract 4 and/or training data compatible with Tesseract 3, and there
are, confusingly, a number of English ones you can find if you poke around--ones
that are optmized for speed, for accuracy, and for backwards compatibility with
Tesseract 3 (see the bottom of the page linked above).
The English training file circled in the folder linked
above is compatible with Tesseract 4 and 3 as of March 2020).
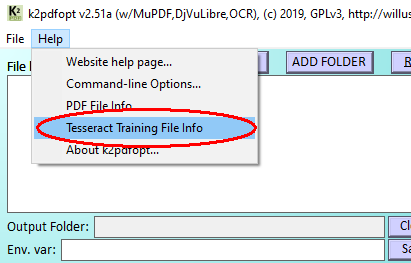
If you want to see what training data is in each file, run
k2pdfopt -ocrlang ? or access the Help menu from the GUI:
Here's what comes up on my system--I have downloaded English, Chinese, and Greek training files.
Note that English is the default because that is my default locale.
TESSDATA_PREFIX environment variable: d:\tesseract-ocr
Tesseract data folder: d:\tesseract-ocr\tessdata
TESSDATA_URL environment variable: (not set)
TESSDATAFAST_URL environment variable: (not set)
Tesseract data URI: https://raw.githubusercontent.com/tesseract-ocr/tessdata_best/master
Locale: English_United States.1252
Contents of d:\tesseract-ocr\tessdata:
File name Size Date Type*
---------------------------------------------------------------------
chi_sim.traineddata 40.14 MB 8-MAR-2016 [TESS]
chi_tra.traineddata 56.29 MB 15-MAR-2020 [LSTM+TESS]
eng-fast.traineddata 3.92 MB 31-MAY-2020 [LSTM]
eng.traineddata [Def] 14.69 MB 12-JUN-2020 [LSTM]
eng_fast.traineddata 3.92 MB 17-MAY-2020 [LSTM]
fra.traineddata 3.79 MB 12-JUN-2020 [LSTM]
grc.traineddata 7.08 MB 8-MAR-2016 [LSTM+TESS]
* - LSTM = "Long Short-Term Memory" training data.
LSTM is the latest, most accurate OCR method used by Tesseract v4.x.
TESS = Tesseract v3.x compatible (can be used by v4.x).
|
A location with some older training files (for Tesseract v3.x)
is on sourceforge.
If you install languge files manually,
you'll need to download the training file to the right folder, e.g.
c:\tesseract-ocr\tessdata.
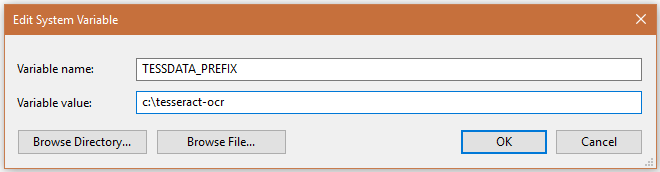
Then
you'll want to set the environment variable TESSDATA_PREFIX to point to the parent folder, e.g. c:\tesseract-ocr as follows (no trailing slash necessary in the latest versions of k2pdfopt):
(You can see how to set an enviroment variable here.)
NOTE: Though the Tesseract folks use the convention above, where the
training data files should be stored in the "tessdata" subfolder of the folder that is pointed to
by TESSDATA_PREFIX, with k2pdfopt (v2.5x and up), you can store the training files
directly in the folder pointed to by TESSDATA_PREFIX. You do not have to put them
in a "tessdata" subfolder. k2pdfopt will find them in either location.
To check that you have the training file(s) in the right place, check the k2pdfopt GUI help
menu as shown above or run k2pdofpt -ocrlang ?
Also, if you have correctly set up Tesseract, you'll see the Tesseract banner when you run k2pdfopt
with OCR turned on, and the selected language will also show:
... or in the GUI conversion window on the first conversion:
UNICODE-16 ALTERNATE LANGUAGE EXAMPLE (SIMPLIFIED CHINESE)
In k2pdfopt v1.63, any language Tesseract OCR supports can be converted to Unicode-16
characters. The example below shows the OCR results on simplified Chinese using
Tesseract v4.0.0 with the latest LSTM training files as of March 2020.
Use the -ocrlang option to select your language. If no language is specified, the
most recently dated training file in the Tesseract training folder is used. Note
that if you use -ocrvis t with a language like Chinese, as an example,
the text will not look right as displayed by the PDF file because k2pdfopt does
not embed any Chinese fonts (or other non-standard fonts) into the PDF file.
But if you copy and paste the text into a Unicode-16 compatible application, it will
come out as Chinese characters.

(Source PDF file) |
|

k2pdfopt -mode copy -ocr t -ocrlang chi_tra crouching_tiger.pdf
(Copied and pasted into translate.google.com) |
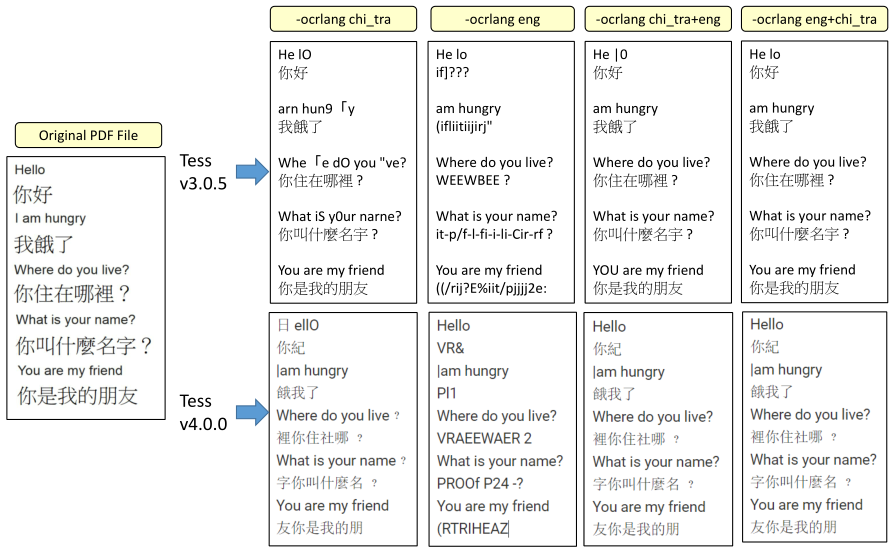
MULTIPLE LANGUAGES
You can specify multiple languages for OCR if you use Tesseract,
e.g. English and Chinese (Example PDF) using
-ocrlang eng+chi_tra
Results with different options (as of k2pdfopt v2.51 / Tesseract v3.0.5 and v4.0.0):
TESSERACT v4.0 OPTIMUM RESOLUTION
An interesting aside about Tesseract v4.0.0--there appears to be an optimum letter height,
in pixels, for getting the best OCR results. I posted this study about it to the Tesseract
google groups forum
in late 2018.
Because of this, k2pdfopt v2.51 and up includes a -ocrdpi option which sets the
dpi of bitmaps passed to Tesseract. The default value should work well in general.
|
|
|
|